
Human Pose Estimations — From 2D to 3D
Identification of human body poses with mere 2D imagery had been a grand challenge in the field machine vision and with the explosion of…

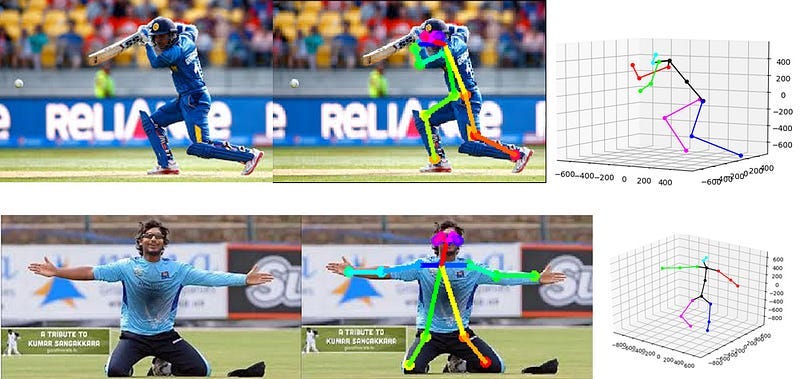
Identification of human body poses with mere 2D imagery had been a grand challenge in the field machine vision and with the explosion of Deep Learning algorithms, the area has seen quite promising advancements recently. As shown in Figure 1, the outputs from these models are able to accurately identify human body keypoints and form skeleton structures depicting the poses. Advancements of these techniques imply great potential with applications in areas such as sports, security surveillance, patient monitoring etc.
The process of human pose estimation can be divided into several parts:
Identifying anatomical keypoints of the human body
The first task is to identify the different parts of a body, preferably joints, so that these points can be tracked in the imagery. The model has to be trained initially using annotated data to be good at this task. Techniques such as heat maps are being widely used at this step and the accuracy directly impacts the nest step
2. Joining the keypoints to form the skeleton structure
Next the identified keypoints have to be joined with each other to form a skeleton structure. This task can be quite tricky as to decide which keypoints should be connected to which. Techniques such as assignment of a confidence score in-between keypoints are used here.
3. Forming a 3D representation of the skeleton structure
So far the process has being able to extract a 2D skeleton structure from the imagery which depicts the pose accurately, but can we derive a 3D model out of this? This can be a very powerful tool to have and as shown in Figure 1 (right), the 3D estimations are somewhat accurate, but there’s surely room for improvements.
4. Executing the above three point for multiple humans in a single image
Identifying the pose of a single human is impressive. Then what about doing that for multiple people in the same image? This question offers a brand new set of challenges in the steps of detecting humans and joining body keypoints.
On top of that, how about executing all these steps in a Real-time implementation? This is where the real deal lies. The research referred in this post tackles this frontier and you can find the paper here-> (https://arxiv.org/abs/1611.08050)
The code found here on my GitHub is based on the tensorflow implementation of the algorithm of the paper open sourced by the authors. (Find the original repo here)
This is quite an interesting frontier in Deep Learning towork in and there are many possibilities to explore!